
1.MySQL数据库
2.SQL语句
01数据库概念
- A: 什么是数据库
数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。 - B: 什么是数据库管理系统
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,
对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据。
02常见的数据库
- A: 常见的数据库
MYSQL :开源免费的数据库,小型的数据库.已经被Oracle收购了.MySQL6.x版本也开始收费。
Oracle :收费的大型数据库,Oracle公司的产品。Oracle收购SUN公司,收购MYSQL。
DB2 :IBM公司的数据库产品,收费的。常应用在银行系统中.
SQLServer:MicroSoft 公司收费的中型的数据库。C#、.net等语言常使用。
SyBase :已经淡出历史舞台。提供了一个非常专业数据建模的工具PowerDesigner。
SQLite : 嵌入式的小型数据库,应用在手机端。
Java相关的数据库:MYSQL,Oracle.
这里使用MySQL数据库。MySQL中可以有多个数据库,数据库是真正存储数据的地方
03数据库和管理系统
* A: 数据库管理系统
1 | ----数据库1 |
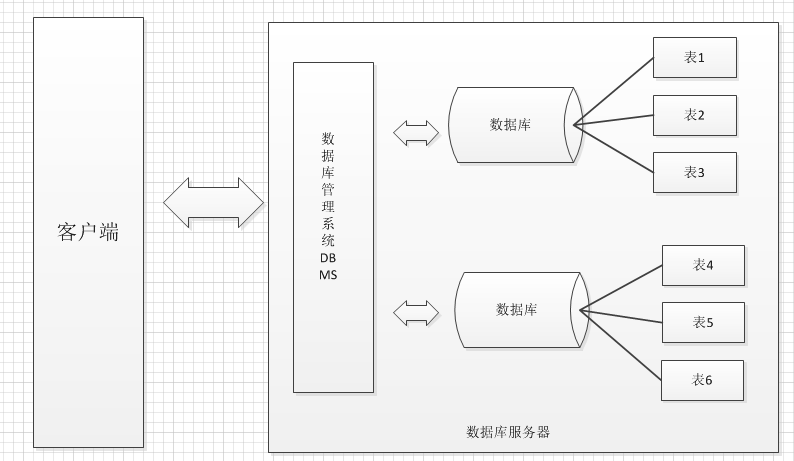
04数据表和Java中类的对应关系
* A:数据库中以表为组织单位存储数据。
1 | 表类似我们的Java类,每个字段都有对应的数据类型。 |
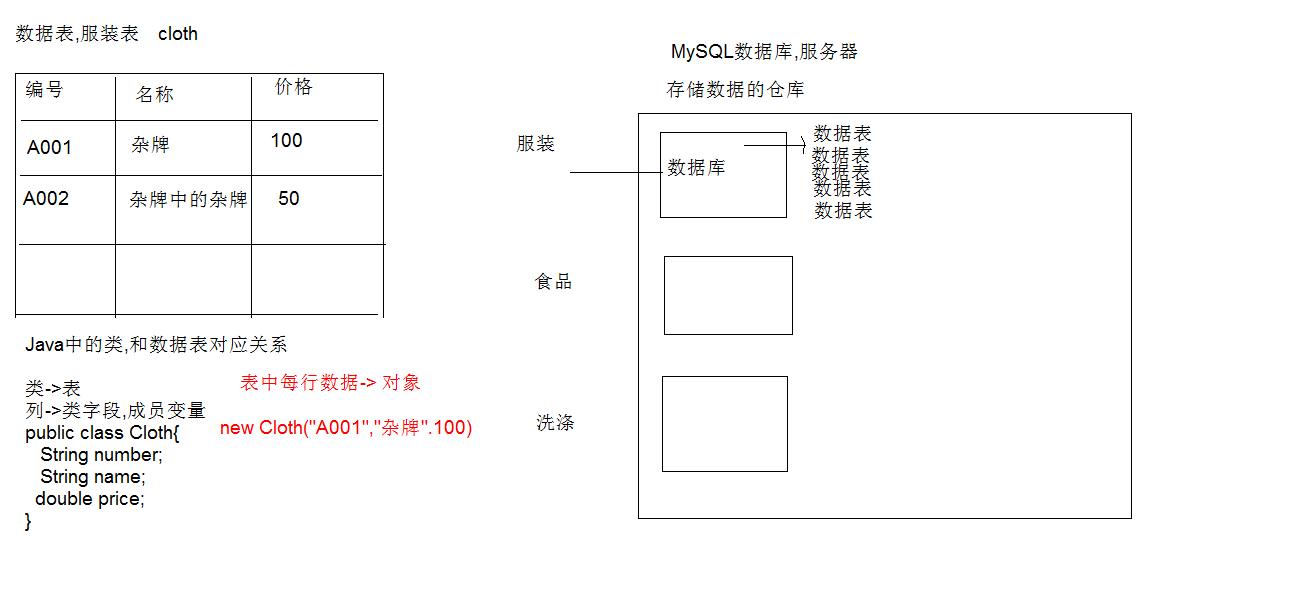
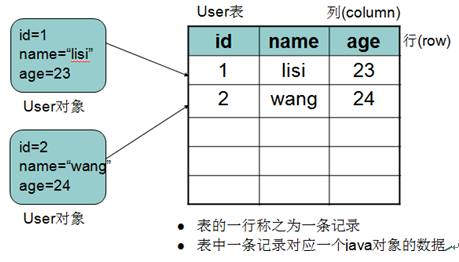
05数据表和Java中类的对应关系用户表举例
* A:举例:
账务表
id name age
1 lisi 23
2 wang 24
每一条记录对应一个User的对象
[user1 id = 1 name = lisi age = 23]
[user2 id = 2 name = wang age = 24]
06MySQL数据库安装
A: 安装步骤参见 day28_source《MySQL安装图解.doc》
B: 安装后,MySQL会以windows服务的方式为我们提供数据存储功能。开启和关闭服务的操作:右键点击我的电脑→管理→服务→可以找到MySQL服务开启或停止。
07数据库在系统服务
- A:开启服务和关闭服务
方式1: 我的电脑—–> (右键)管理—->服务和应用程序—->服务—-找到MySQL服务右键启动或关闭
方式2: 进入dos窗口 使用命令: net start mysql 开启MySQL服务; 命令:net stop mysql 关闭MySql服务
08MySQL的登录
1 | * A: MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,使用安装时设置的密码即可登录。 |
09SQLYog软件介绍
* A: 具体参见 《SQLYog配置.doc》
10SQL语句介绍和分类
- A:SQL介绍
- 前面学习了接口的代码体现,现在来学习接口的思想,接下里从生活中的例子进行说明。
- 举例:我们都知道电脑上留有很多个插口,而这些插口可以插入相应的设备,这些设备为什么能插在上面呢?
- 主要原因是这些设备在生产的时候符合了这个插口的使用规则,否则将无法插入接口中,更无法使用。发现这个插口的出现让我们使用更多的设备。
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
创建数据库、创建数据表、向数据表中添加一条条数据信息均需要使用SQL语句
1 | * B: SQL分类 |
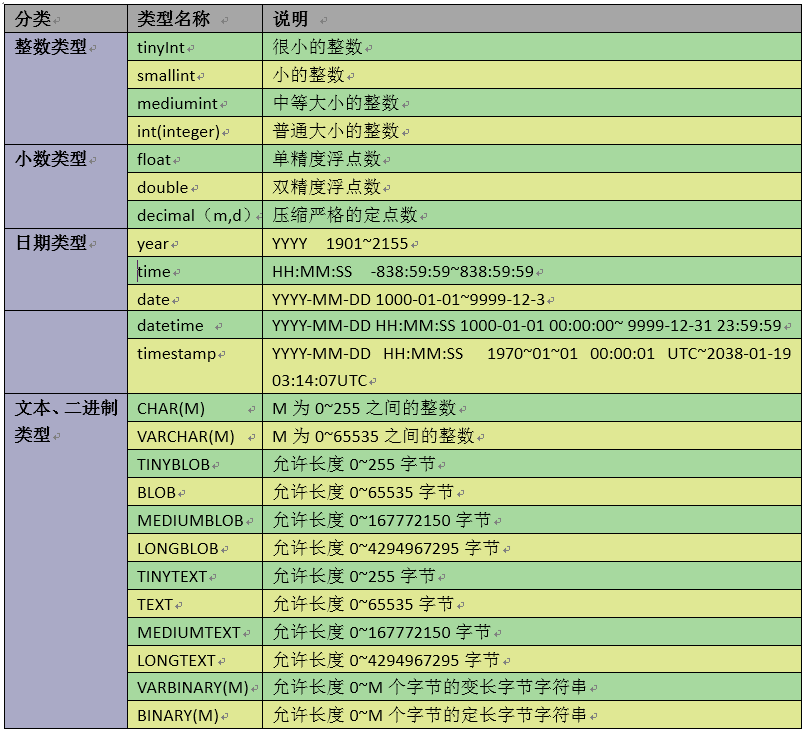
11数据表中的数据类型

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27* A:MySQL中的我们常使用的数据类型如下
详细的数据类型如下(不建议详细阅读!)
分类 类型名称 说明
整数类型 tinyInt 很小的整数
smallint 小的整数
mediumint 中等大小的整数
int(integer) 普通大小的整数
小数类型 float 单精度浮点数
double 双精度浮点数
decimal(m,d) 压缩严格的定点数
日期类型 year YYYY 1901~2155
time HH:MM:SS -838:59:59~838:59:59
date YYYY-MM-DD 1000-01-01~9999-12-3
datetime YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59
timestamp YYYY-MM-DD HH:MM:SS 1970~01~01 00:00:01 UTC~2038-01-19 03:14:07UTC
文本、二进制类型 CHAR(M) M为0~255之间的整数
VARCHAR(M) M为0~65535之间的整数
TINYBLOB 允许长度0~255字节
BLOB 允许长度0~65535字节
MEDIUMBLOB 允许长度0~167772150字节
LONGBLOB 允许长度0~4294967295字节
TINYTEXT 允许长度0~255字节
TEXT 允许长度0~65535字节
MEDIUMTEXT 允许长度0~167772150字节
LONGTEXT 允许长度0~4294967295字节
VARBINARY(M)允许长度0~M个字节的变长字节字符串
BINARY(M) 允许长度0~M个字节的定长字节字符串
12创建数据库操作
1 | * A: 创建数据库 |
13创建数据表格式
1 | * A:格式: |
14约束
1 | * A: 约束的作用: void test() |
15SQL代码的保存
1 | * A: 当sql语句执行了,就已经对数据库进行操作了,一般不用保存操作 |
16创建用户表
1 | * A: 创建用户表: |
17主键约束
1 | * A: 主键是用于标识当前记录的字段。它的特点是非空,唯一。 |
18常见表的操作
1 | * A:"查看表":"查看数据库中的所有表": |
19修改表结构
1 | * A: "修改表添加列" |
20数据表添加数据_1
1 | * A: -- "向表中插入某些列" |
21数据表添加数据_2
1 | * A: "添加数据格式,不考虑主键" |
22更新数据
1 | * A: "用来修改指定条件的数据,将满足条件的记录指定列修改为指定值" |
23删除数据
1 | * A: 语法: |
24命令行乱码问题
1 | A: 问题 |
25数据表和测试数据准备
1 | * A: 查询语句,在开发中使用的次数最多,此处使用“zhangwu” 账务表。 |
26数据的基本查询
1 | * A: "查询指定字段信息" |
27数据的条件查询_1
1 | * A:条件查询 |
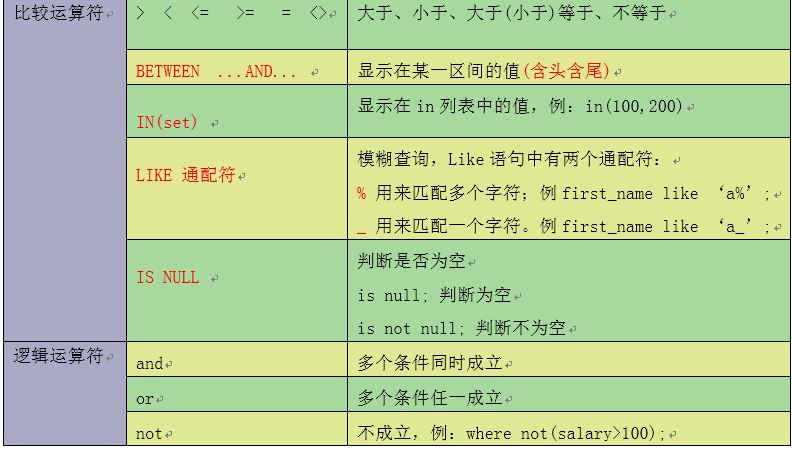
28数据的条件查询_2
1 | * A "模糊查询" |
29排序查询
1 | * A: 排序查询 |
30聚合函数
1 | * A: 聚合函数 |
31分组查询
1 | * A: 分组查询 |
