
1、List接口
2、ArrayList集合、LinkedList集合
3、Set接口
4、哈希表(Hash table)
5、HashSet集合、LinkedHashSet集合、TreeSet集合
6、判断集合唯一性原理
7、Queue接口(队列)
8、PrioritQueue 优先级队列
9、Deque 接口(双端队列)、ArrayDeque 实现类
01List接口的特点
1 | A:List接口的特点: |
02List接口的特有方法
1 | A:List接口的特有方法(带索引的方法) |
03迭代器的并发修改异常
1 | A:迭代器的并发修改异常 |
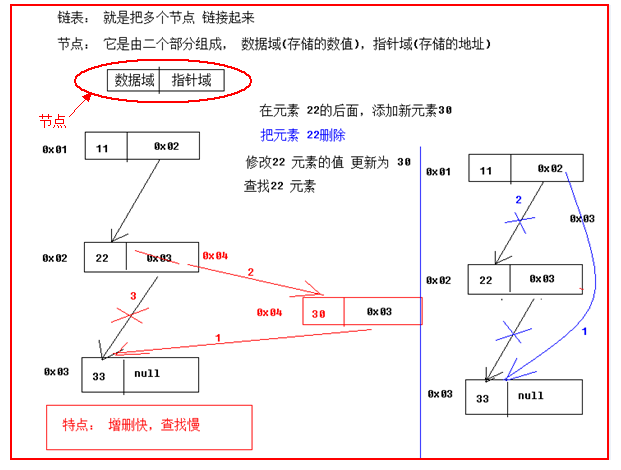
04数据的存储结构
1 | A:数据的存储结构 |
05ArrayList集合的自身特点
1 | A:ArrayList集合的自身特点 |
06LinkedList集合的自身特点
1 | A:LinkedList集合的自身特点 |
07LinkedList特有方法
1 | 具体查看 :"25 Deque 接口(双端队列)与 ArrayDeque 实现类、LinkedList 实现类" |
08 各List实现类的性能分析,集合Vector类的特点,
1 | Java 提供的 List 就是一个线性表接口, |

09Set接口的特点
1 | Set接口类似于个"罐子","程序可以依次把多个对象“丢进”Set集合", |
10Set集合存储和迭代(以HashSet为例)
1 | A:Set集合存储和迭代 |
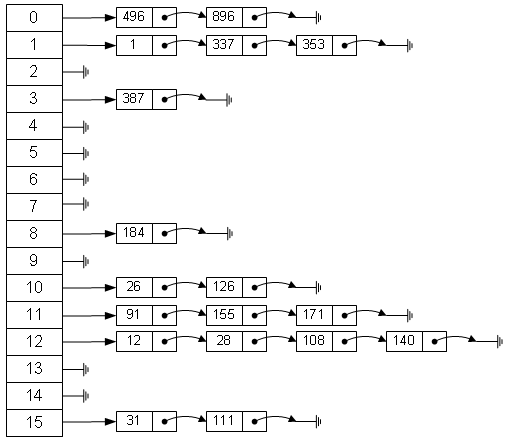
11哈希表的数据结构
1 | A:哈希表的数据结构:(参见图解) |
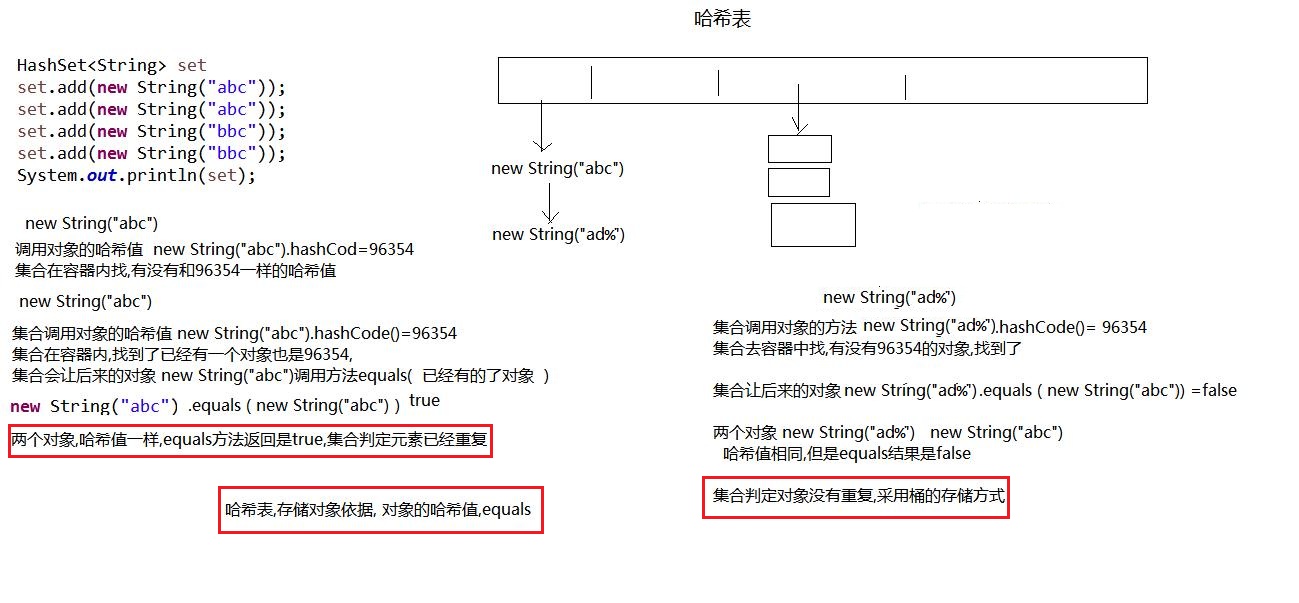
12字符串对象的哈希值(HashCode)
1 | A:字符串对象的哈希值 |
13哈希表的存储过程
1 | A:哈希表的存储原理 |
——————————————————————————————————————————————————————————————————————
——————————————————————————————————————————————————————————————————————
——————————————————————————————————————————————————————————————————————
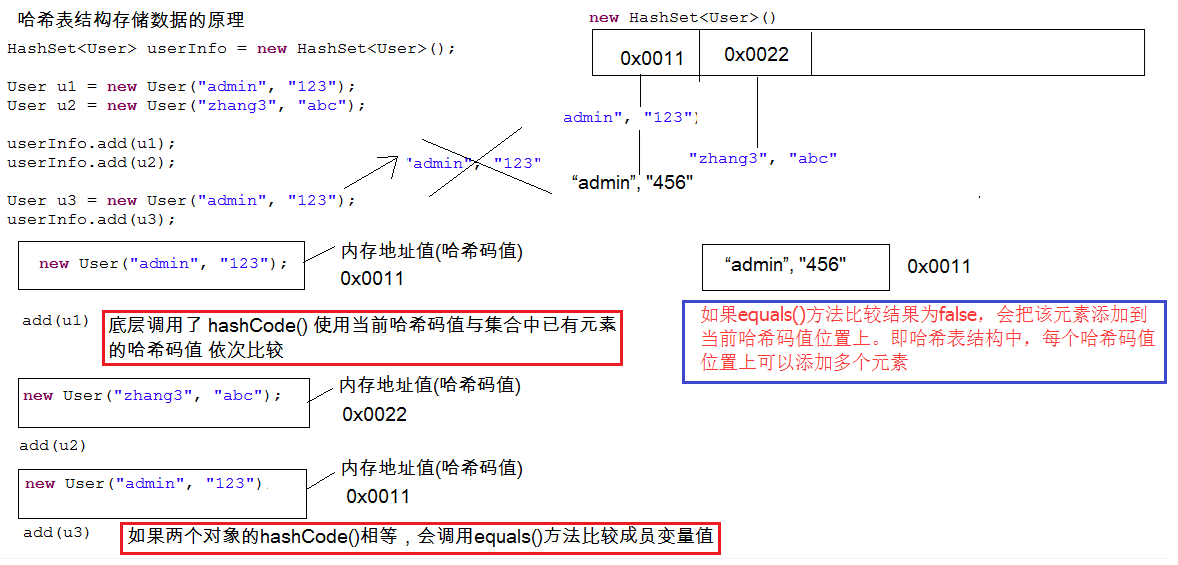
14HashSet存储自定义的对象
1 | A:HashSet存储自定义的对象 |
15自定义对象重写hashCode和equals方法
1 | A:自定义对象重写hashCode和equals方法 |
16LinkedHashSet集合
1 | A:LinkedHashSet集合 |
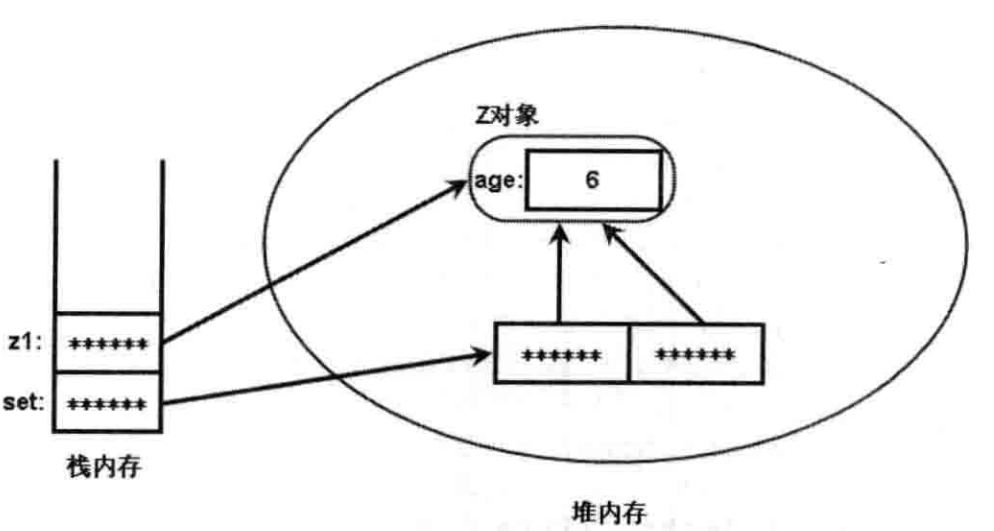
17ArrayList,HashSet判断对象是否重复的原理
1 | ArrayList,HashSet判断对象是否重复的原理 |
18hashCode和equals方法的面试题
1 | A:hashCode和equals的面试题 |
19TreeSet类
1 | TreeSet 类与散列集HashSet十分类似, 不过, 它比HashSet有所改进。 |
20TreeSet类的自然排序和定制排序
1 | 1. 自然排序 |
21TreeSet类判断对象是否重复的原理
1 | 对于TreeSet集合,判断"两个对象是否相等"的"唯一标准"是: |
22各Set实现类的性能分析
1 | HashSet 和 TreeSet 是 Set 的两个典型实现 ,到底如何选择HashSet 和 TreeSet 呢? |
23 Queue(队列)集合
1 | Queue 用于模拟队列这种数据结构 , 队列通常是指"先进先出" (FIFO ) 的容器 。 |
24 Priority Queue 优先级队列
1 | "PriorityQueue" 是一个比较标准的队列实现类 ,但"不是绝对标准"的"队列"实现, |
25 Deque 接口(双端队列)与 ArrayDeque 实现类、LinkedList 实现类
1 | ~ void addFirst(Object e): 将指定元素插入该双端队列的开头。 |
小结
1 | List与Set集合的区别? |
